












.avif)










While many tools offer features like CAPTCHA solver and IP rotation for collecting data from websites that prohibit data scraping, using them is not recommended. By signing up on any website, you agree to their terms of service and policies, and breaking them could lead to banning or even legal actions.
To help you scrape data ethically, this guide will teach you how to zero in on websites that allow web scraping. You'll also find examples of proven pro-scraping sites, as well as a recommendation for a web scraping tool that can help you extract data seamlessly and responsibly.
TL;DR
- You can verify whether a website allows scraping by checking its robots.txt file, HTTP headers, terms of service, and any Open Data initiative mentions.
- Many websites across finance, sports, weather, public databases, job boards, and travel actively permit scraping or provide official APIs for it.
- Public data is generally safe to scrape; personally identifiable information (PII) is subject to GDPR and CCPA restrictions, and copyrighted data requires explicit permission.
- Tools like Clay combine web scraping with waterfall enrichment across 150+ data providers, letting you extract, enrich, and act on data in one workflow.
Why Do Websites Allow Web Scraping?
While some websites and platforms prohibit scraping to protect their users' privacy, extracting publicly available data is still legal, as long as it complies with the respective country's laws and regulations. Luckily, many websites permit scraping for their own benefits, including:
- 🚀 Increased traffic: The scraped data can reach new audiences and lead them back to the original site for more details
- 🔄 Data sharing: Websites that embrace open data ethos allow and encourage scraping to let anyone use their data without restrictions
- ⚖️ Control and regulation: Websites that allow web scraping through an API can control the volume and frequency of requests and allow access only to authorized users
- 🤝 Community development: Ethical scraping can create a community around the website, with people sharing tips and guides and even creating tools that can improve the website
6 Ways To Identify Websites That Allow Web Scraping

To ensure you're scraping data ethically, take the following steps to verify each platform's stance on data scraping:
- Check the robots.txt file
- Look for an official scraping API
- Read the terms of service
- Inspect HTTP headers
- Asses the data found on the website
- Check for Open Data initiatives
1. Read the Robots.txt File
A robots.txt file is the root of a website that tells scrapers whether they can extract data and which pages they can access.
You can find the file by adding robots.txt to the end of the domain of the website you want to scrape. For example:
If a website doesn't have a robots.txt file or hasn't specified otherwise, it may implicitly allow file scraping. Still, to stay on the safe side, consider the other indicators we discuss in this guide.
That said, web scrapers are not obligated to follow the instructions in the robots.txt file, but it should help you understand where the website stands on scraping.
2. Look for a Scraping API
Some websites that allow web scraping provide an official scraping API for users to integrate. Some of the popular solutions include:
By offering a scraping API, the website can control the volume and frequency of requests to avoid overloading its servers. It also helps enhance data security through encryption and access controls, ensures data integrity by offering it in reliable formats, and eliminates data errors inherent in using web scrapers. 💻
To check if a website has a scraping API:
- Search its documentation for sections like API and Developers
- Google [website name] API
- Check the site footer or sitemap
3. Read the Terms of Service
Sites that allow web scraping may explicitly state it in their terms and service, alongside guidelines on how to scrape and use the data responsibly.
You can check by opening the terms of service page and searching for words like scraping, data use, and crawling. If anything is unclear, you can contact the support team for consultation. 🗣️
4. Inspect HTTP Headers
Some websites set the X-Robots-Tag HTTP header to control the behavior of scrapers at a more detailed level than using the robots.txt file. While primarily designed to instruct search engine crawlers on how to interact with a website's resources, it can also work with web scrapers.
Like the robots.txt file, the X-Robots-Tag doesn't block access to the website's resources. Its effectiveness depends on web scrapers respecting its directives. Still, the header can help you understand a website's stand on web scraping.
Here's how to check the HTTP header of a website using your browser's developer tools:
- Load the URL in Chrome and open the developer tools by pressing Ctrl+Shift+I or right-clicking on the page and selecting Inspect
- Click the Network tab
- Reload the page and click on the file on the left side of the panel
- Check the right side of the panel for the HTTP header info
You can also check by installing the Web Developer plugin or Robots Exclusion Checker extension in Chrome or by creating a simple Python script. ⌨️
5. Assess the Type of Data on the Website
There are three general types of website data: public, personal, and copyrighted. Here's what each of them may look like:
| Public Data | Personal Data | Copyrighted Data |
|---|---|---|
| Public news articles | Names | Articles |
| Wikipedia pages | Addresses | Videos |
| Public social media posts | Dates of birth | Pictures |
| Public profiles | Biometric data | Music |
| Product listings on e-commerce platforms | Phone numbers | Databases |
In the context of scraping, public data is the information you can access without a login. A website featuring this type of information is generally safe for scraping unless it explicitly prohibits it in its robots.txt file, HTTP headers, or terms of use.
On the other hand, there are no universal guidelines on scraping personally identifiable information (PII). Each jurisdiction has different regulations. The two most notable are the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), which prohibit PII collection, storage, and use without a lawful reason and the owner's explicit consent.
Websites with copyrighted data can prohibit scraping depending on how you plan to use it. Copyrighted data is owned by individuals or businesses with explicit control over its collection and reproduction. 📁
💡 Bonus read: Check out these articles that offer solutions for scraping:
6. Check for Open Data Initiatives
Some websites participate in Open Data initiatives and provide free access to datasets anyone can freely use and redistribute. They usually have explicit permissions for scraping and exporting data, which you can find in the terms and conditions.
To check if a website embraces the open data ethos, look for mentions of the Open Data on the About Us page.
💡 Tip: If the six methods above still don't clarify the website's stance, contact the admin or owner for permission or clarification on the approved data scraping methods or channels.
Which Websites Allow Web Scraping?

Below, you'll find recommendations of websites to scrape data from, grouped into the following categories:
- Finance
- Sports
- Weather
- Public databases
- Job boards
- Travel and hospitality
Finance 💲
Websites that provide information and tools related to finances, such as real-time and historical market data and financial news, often allow scraping. Examples include:
Sports ⚽
Sports websites that provide comprehensive sports coverage can allow fans, analysts, and researchers to scrape data like league standings and performance stats for players and teams. Examples include:
Weather ☔
Weather websites have data like forecasts and current conditions, which can be valuable in a wide range of industries, including sports, mining, agriculture, and construction. Examples include:
Public Databases 📂🌐
Public databases contain data on crime, health, employment, regulations, demographics, and other public records, which are free to scrape, reuse, and redistribute without restrictions. Examples include:
Job Boards 👷
Job boards allow web scraping data like job titles and descriptions and company names. Examples include:
Travel and Hospitality ✈️
Travel and hospitality websites can allow scraping prices, flights, hotels, and destinations to help with travel planning and booking. Examples include:
Best Practices When Scraping Websites That Allow Web Scraping
Once you've found the website you want to scrape, consider these tips to extract data effectively while remaining respectful of the website's resources:
| Tip | Explanation |
|---|---|
| ⌛ Don't overload the server | Avoid making too many requests in a short time by adding a delay between requests or conducting your scraping activities in off-peak hours. This will prevent interference with the website's normal operations |
| ⚒️ Use the website APIs | Using an official API lets you scrape safely and prevents you from collecting any data that isn't publicly available |
| 📝 Be ethical | Although you are not obligated to follow the instructions, respect the robots.txt file, HTTP header, and terms of use |
| 🗺️ Follow the sitemap | The sitemap contains information about the types of files on the website, and following it can simplify your web scraping project |
| ©️ Don't violate copyright | Do not scrape copyrighted data unless you get explicit permission or adhere to the fair use doctrine |
| ⚖️ Don't breach GDPR or CCPA | Do not scrape the PII of EU or California citizens without explicit permission from the owners or a lawful reason |
How To Extract High-Quality Data From Sites That Allow Web Scraping
While manually extracting data is possible, large-scale projects require a web data scraper as it's more practical than opening each page and copy-pasting the information you need. With a robust data scraper, you can extract high-quality data from thousands, or even millions, of pages quickly and efficiently.
That said, not all tools are created equal, so look for one that ticks the following boxes:
- ✔️ Is easy to use
- ✔️ Has automation and scheduling features
- ✔️ Exports the results in multiple forms and file formats
- ✔️ Is capable of handling all types of websites, including complex websites with dynamic elements
To minimize costs, look for a data scraper with enrichment features to collect and consolidate data from multiple sources and ensure your results are accurate, current, and relevant. Such a centralized solution can help you save time, money, and human resources. 💸
If you're looking for a recommendation on a tool that lets you extract, format, and enrich high-quality data consistently, Clay is the way to go. It taps into more than 50 databases to find the information you need, as discussed in detail below. 👇
How Clay Can Help You Scrape High-Quality Data
Clay is a comprehensive data providing and enrichment platform with robust scraping capabilities. It offers two native and automated features that let you collect data from the web:
- AI scraping assistant
- Chrome extension
Claygent is an AI data scraper that lets you scrape websites through prompts. All you have to do is tell the assistant what data points you need and where to get them from. Claygent will find and organize the results for you in a few seconds.
You can use it to find details about people and companies without lifting a finger, making it the ideal scraper if you are new to scraping or want a hands-off way to extract data. 💪

If you want to scrape data as you browse, use Clay's Chrome Extension. It collects info automatically when you open a page. You can also create custom data scraping recipes to meet your unique needs without coding. 🖱️
While impressive, web scraping is just the tip of the iceberg when it comes to Clay's functionality. The platform offers numerous data enrichment tools to fill in any missing points.
Maximize Data Coverage With Clay
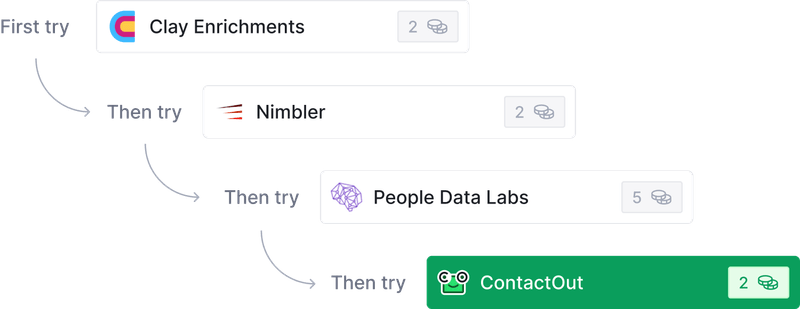
After scraping, leverage Clay's state-of-the-art data enrichment features to improve the quality of your results. Unlike typical web scrapers, Clay integrates with dozens of data providers, giving you unrivaled coverage and reliability.
To enrich your results, Clay lets you choose the data providers to tap into and uses waterfall enrichment to check each database one by one until it finds the info you need. You only pay for the information you find, which helps avoid cost overruns. 💵
After enriching your data, you can push it to your CRM, export it as a CSV file, or, if you are running an outbound campaign, use the AI email drafter to create hyper-personalized emails for each lead. 📧

Find Clay's Endless Possibilities
The impressive scraping and enrichment features are only the beginning. Clay has over 100 integrations, many of which can simplify the process of extracting data. The table below highlights some of them:
| Integration | Function |
|---|---|
| ⭐ Parse Data From URL | Uses ScrapeMagic API to parse data from a webpage |
| ⭐ Find Business Reviews Information | Takes business name, website, or address and returns Google review rating, number of reviews, and other business information |
| ⭐ Find Keywords in Website | Checks a specific website for certain keywords or phrases |
| ⭐ Get Products | Extracts a list of products and their details from a Shopify store URL |
The platform also offers dozens of templates that come with pre-built Clay tables and automations to help you perform various scraping tasks, such as:
- Scraping Google Maps
- Scraping Indeed jobs
- Enriching inbound leads
- Finding the number of open roles and employees in a company 🔍
Many individuals and marketing and sales pros who've tried Clay are in awe of what it can do. Here's what one of them had to say about it:

Create Your Clay Account
You can explore Clay's features in three quick steps:
- Go to the signup page 👈
- Add your name and email address
- Enjoy the platform's capabilities
Clay offers a free forever plan that lets you test the platform. If you like what you see, opt for one of the four paid plans outlined in the table below:
| Plan | Number of Data Credits | Price |
|---|---|---|
| Launch | 2,500–10,000/month | $185/month |
| Growth | 6,000–100,000/month | $495/month |
| Enterprise | Custom | Custom |
If you want to know more about the platform and what it can do, check out Clay University and join the Slack community. To stay updated on the latest tips and features, sign up for Clay's newsletter. 💌
Frequently Asked Questions
Is web scraping legal?
Scraping publicly available data is generally legal, provided it complies with the laws of the relevant jurisdiction. However, scraping personally identifiable information (PII) without consent may violate GDPR or CCPA, and scraping copyrighted content without permission can create legal exposure. Always check a site's terms of service before scraping.
How do I know if a website allows web scraping?
Check the site's robots.txt file, review its terms of service for mentions of scraping or crawling, inspect HTTP headers for X-Robots-Tag directives, and look for an official API. If the site participates in Open Data initiatives, it will typically say so on its About Us page. When in doubt, contact the site owner directly.
What is the difference between scraping public data and personal data?
Public data is information accessible without a login, such as news articles, public profiles, and product listings. It is generally safe to scrape unless explicitly prohibited. Personal data includes names, addresses, phone numbers, and biometric data. Scraping PII is subject to strict regulations under GDPR and CCPA and requires a lawful basis and the owner's explicit consent.
Which types of websites most commonly allow web scraping?
Finance sites (Yahoo Finance, Google Finance), sports reference sites, weather platforms, public government databases, job boards, and travel booking sites are among the most common categories that permit scraping. Many provide official APIs to make structured data access even easier.
📚 Keep reading: For more interesting content, check out these articles on scraping social media platforms, including:
While many tools offer features like CAPTCHA solver and IP rotation for collecting data from websites that prohibit data scraping, using them is not recommended. By signing up on any website, you agree to their terms of service and policies, and breaking them could lead to banning or even legal actions.
To help you scrape data ethically, this guide will teach you how to zero in on websites that allow web scraping. You'll also find examples of proven pro-scraping sites, as well as a recommendation for a web scraping tool that can help you extract data seamlessly and responsibly.
TL;DR
- You can verify whether a website allows scraping by checking its robots.txt file, HTTP headers, terms of service, and any Open Data initiative mentions.
- Many websites across finance, sports, weather, public databases, job boards, and travel actively permit scraping or provide official APIs for it.
- Public data is generally safe to scrape; personally identifiable information (PII) is subject to GDPR and CCPA restrictions, and copyrighted data requires explicit permission.
- Tools like Clay combine web scraping with waterfall enrichment across 150+ data providers, letting you extract, enrich, and act on data in one workflow.
Why Do Websites Allow Web Scraping?
While some websites and platforms prohibit scraping to protect their users' privacy, extracting publicly available data is still legal, as long as it complies with the respective country's laws and regulations. Luckily, many websites permit scraping for their own benefits, including:
- 🚀 Increased traffic: The scraped data can reach new audiences and lead them back to the original site for more details
- 🔄 Data sharing: Websites that embrace open data ethos allow and encourage scraping to let anyone use their data without restrictions
- ⚖️ Control and regulation: Websites that allow web scraping through an API can control the volume and frequency of requests and allow access only to authorized users
- 🤝 Community development: Ethical scraping can create a community around the website, with people sharing tips and guides and even creating tools that can improve the website
6 Ways To Identify Websites That Allow Web Scraping
To ensure you're scraping data ethically, take the following steps to verify each platform's stance on data scraping:
- Check the robots.txt file
- Look for an official scraping API
- Read the terms of service
- Inspect HTTP headers
- Asses the data found on the website
- Check for Open Data initiatives
1. Read the Robots.txt File
A robots.txt file is the root of a website that tells scrapers whether they can extract data and which pages they can access.
You can find the file by adding robots.txt to the end of the domain of the website you want to scrape. For example:
If a website doesn't have a robots.txt file or hasn't specified otherwise, it may implicitly allow file scraping. Still, to stay on the safe side, consider the other indicators we discuss in this guide.
That said, web scrapers are not obligated to follow the instructions in the robots.txt file, but it should help you understand where the website stands on scraping.
2. Look for a Scraping API
Some websites that allow web scraping provide an official scraping API for users to integrate. Some of the popular solutions include:
By offering a scraping API, the website can control the volume and frequency of requests to avoid overloading its servers. It also helps enhance data security through encryption and access controls, ensures data integrity by offering it in reliable formats, and eliminates data errors inherent in using web scrapers. 💻
To check if a website has a scraping API:
- Search its documentation for sections like API and Developers
- Google [website name] API
- Check the site footer or sitemap
3. Read the Terms of Service
Sites that allow web scraping may explicitly state it in their terms and service, alongside guidelines on how to scrape and use the data responsibly.
You can check by opening the terms of service page and searching for words like scraping, data use, and crawling. If anything is unclear, you can contact the support team for consultation. 🗣️
4. Inspect HTTP Headers
Some websites set the X-Robots-Tag HTTP header to control the behavior of scrapers at a more detailed level than using the robots.txt file. While primarily designed to instruct search engine crawlers on how to interact with a website's resources, it can also work with web scrapers.
Like the robots.txt file, the X-Robots-Tag doesn't block access to the website's resources. Its effectiveness depends on web scrapers respecting its directives. Still, the header can help you understand a website's stand on web scraping.
Here's how to check the HTTP header of a website using your browser's developer tools:
- Load the URL in Chrome and open the developer tools by pressing Ctrl+Shift+I or right-clicking on the page and selecting Inspect
- Click the Network tab
- Reload the page and click on the file on the left side of the panel
- Check the right side of the panel for the HTTP header info
You can also check by installing the Web Developer plugin or Robots Exclusion Checker extension in Chrome or by creating a simple Python script. ⌨️
5. Assess the Type of Data on the Website
There are three general types of website data: public, personal, and copyrighted. Here's what each of them may look like:
| Public Data | Personal Data | Copyrighted Data |
|---|---|---|
| Public news articles | Names | Articles |
| Wikipedia pages | Addresses | Videos |
| Public social media posts | Dates of birth | Pictures |
| Public profiles | Biometric data | Music |
| Product listings on e-commerce platforms | Phone numbers | Databases |
In the context of scraping, public data is the information you can access without a login. A website featuring this type of information is generally safe for scraping unless it explicitly prohibits it in its robots.txt file, HTTP headers, or terms of use.
On the other hand, there are no universal guidelines on scraping personally identifiable information (PII). Each jurisdiction has different regulations. The two most notable are the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), which prohibit PII collection, storage, and use without a lawful reason and the owner's explicit consent.
Websites with copyrighted data can prohibit scraping depending on how you plan to use it. Copyrighted data is owned by individuals or businesses with explicit control over its collection and reproduction. 📁
💡 Bonus read: Check out these articles that offer solutions for scraping:
6. Check for Open Data Initiatives
Some websites participate in Open Data initiatives and provide free access to datasets anyone can freely use and redistribute. They usually have explicit permissions for scraping and exporting data, which you can find in the terms and conditions.
To check if a website embraces the open data ethos, look for mentions of the Open Data on the About Us page.
💡 Tip: If the six methods above still don't clarify the website's stance, contact the admin or owner for permission or clarification on the approved data scraping methods or channels.
Which Websites Allow Web Scraping?
Below, you'll find recommendations of websites to scrape data from, grouped into the following categories:
- Finance
- Sports
- Weather
- Public databases
- Job boards
- Travel and hospitality
Finance 💲
Websites that provide information and tools related to finances, such as real-time and historical market data and financial news, often allow scraping. Examples include:
Sports ⚽
Sports websites that provide comprehensive sports coverage can allow fans, analysts, and researchers to scrape data like league standings and performance stats for players and teams. Examples include:
Weather ☔
Weather websites have data like forecasts and current conditions, which can be valuable in a wide range of industries, including sports, mining, agriculture, and construction. Examples include:
Public Databases 📂🌐
Public databases contain data on crime, health, employment, regulations, demographics, and other public records, which are free to scrape, reuse, and redistribute without restrictions. Examples include:
Job Boards 👷
Job boards allow web scraping data like job titles and descriptions and company names. Examples include:
Travel and Hospitality ✈️
Travel and hospitality websites can allow scraping prices, flights, hotels, and destinations to help with travel planning and booking. Examples include:
Best Practices When Scraping Websites That Allow Web Scraping
Once you've found the website you want to scrape, consider these tips to extract data effectively while remaining respectful of the website's resources:
| Tip | Explanation |
|---|---|
| ⌛ Don't overload the server | Avoid making too many requests in a short time by adding a delay between requests or conducting your scraping activities in off-peak hours. This will prevent interference with the website's normal operations |
| ⚒️ Use the website APIs | Using an official API lets you scrape safely and prevents you from collecting any data that isn't publicly available |
| 📝 Be ethical | Although you are not obligated to follow the instructions, respect the robots.txt file, HTTP header, and terms of use |
| 🗺️ Follow the sitemap | The sitemap contains information about the types of files on the website, and following it can simplify your web scraping project |
| ©️ Don't violate copyright | Do not scrape copyrighted data unless you get explicit permission or adhere to the fair use doctrine |
| ⚖️ Don't breach GDPR or CCPA | Do not scrape the PII of EU or California citizens without explicit permission from the owners or a lawful reason |
How To Extract High-Quality Data From Sites That Allow Web Scraping
While manually extracting data is possible, large-scale projects require a web data scraper as it's more practical than opening each page and copy-pasting the information you need. With a robust data scraper, you can extract high-quality data from thousands, or even millions, of pages quickly and efficiently.
That said, not all tools are created equal, so look for one that ticks the following boxes:
- ✔️ Is easy to use
- ✔️ Has automation and scheduling features
- ✔️ Exports the results in multiple forms and file formats
- ✔️ Is capable of handling all types of websites, including complex websites with dynamic elements
To minimize costs, look for a data scraper with enrichment features to collect and consolidate data from multiple sources and ensure your results are accurate, current, and relevant. Such a centralized solution can help you save time, money, and human resources. 💸
If you're looking for a recommendation on a tool that lets you extract, format, and enrich high-quality data consistently, Clay is the way to go. It taps into more than 50 databases to find the information you need, as discussed in detail below. 👇
How Clay Can Help You Scrape High-Quality Data
Clay is a comprehensive data providing and enrichment platform with robust scraping capabilities. It offers two native and automated features that let you collect data from the web:
- AI scraping assistant
- Chrome extension
Claygent is an AI data scraper that lets you scrape websites through prompts. All you have to do is tell the assistant what data points you need and where to get them from. Claygent will find and organize the results for you in a few seconds.
You can use it to find details about people and companies without lifting a finger, making it the ideal scraper if you are new to scraping or want a hands-off way to extract data. 💪
If you want to scrape data as you browse, use Clay's Chrome Extension. It collects info automatically when you open a page. You can also create custom data scraping recipes to meet your unique needs without coding. 🖱️
While impressive, web scraping is just the tip of the iceberg when it comes to Clay's functionality. The platform offers numerous data enrichment tools to fill in any missing points.
Maximize Data Coverage With Clay
After scraping, leverage Clay's state-of-the-art data enrichment features to improve the quality of your results. Unlike typical web scrapers, Clay integrates with dozens of data providers, giving you unrivaled coverage and reliability.
To enrich your results, Clay lets you choose the data providers to tap into and uses waterfall enrichment to check each database one by one until it finds the info you need. You only pay for the information you find, which helps avoid cost overruns. 💵
After enriching your data, you can push it to your CRM, export it as a CSV file, or, if you are running an outbound campaign, use the AI email drafter to create hyper-personalized emails for each lead. 📧
Find Clay's Endless Possibilities
The impressive scraping and enrichment features are only the beginning. Clay has over 100 integrations, many of which can simplify the process of extracting data. The table below highlights some of them:
| Integration | Function |
|---|---|
| ⭐ Parse Data From URL | Uses ScrapeMagic API to parse data from a webpage |
| ⭐ Find Business Reviews Information | Takes business name, website, or address and returns Google review rating, number of reviews, and other business information |
| ⭐ Find Keywords in Website | Checks a specific website for certain keywords or phrases |
| ⭐ Get Products | Extracts a list of products and their details from a Shopify store URL |
The platform also offers dozens of templates that come with pre-built Clay tables and automations to help you perform various scraping tasks, such as:
- Scraping Google Maps
- Scraping Indeed jobs
- Enriching inbound leads
- Finding the number of open roles and employees in a company 🔍
Many individuals and marketing and sales pros who've tried Clay are in awe of what it can do. Here's what one of them had to say about it:
Create Your Clay Account
You can explore Clay's features in three quick steps:
- Go to the signup page 👈
- Add your name and email address
- Enjoy the platform's capabilities
Clay offers a free forever plan that lets you test the platform. If you like what you see, opt for one of the four paid plans outlined in the table below:
| Plan | Number of Data Credits | Price |
|---|---|---|
| Launch | 2,500–10,000/month | $185/month |
| Growth | 6,000–100,000/month | $495/month |
| Enterprise | Custom | Custom |
If you want to know more about the platform and what it can do, check out Clay University and join the Slack community. To stay updated on the latest tips and features, sign up for Clay's newsletter. 💌
Frequently Asked Questions
Is web scraping legal?
Scraping publicly available data is generally legal, provided it complies with the laws of the relevant jurisdiction. However, scraping personally identifiable information (PII) without consent may violate GDPR or CCPA, and scraping copyrighted content without permission can create legal exposure. Always check a site's terms of service before scraping.
How do I know if a website allows web scraping?
Check the site's robots.txt file, review its terms of service for mentions of scraping or crawling, inspect HTTP headers for X-Robots-Tag directives, and look for an official API. If the site participates in Open Data initiatives, it will typically say so on its About Us page. When in doubt, contact the site owner directly.
What is the difference between scraping public data and personal data?
Public data is information accessible without a login, such as news articles, public profiles, and product listings. It is generally safe to scrape unless explicitly prohibited. Personal data includes names, addresses, phone numbers, and biometric data. Scraping PII is subject to strict regulations under GDPR and CCPA and requires a lawful basis and the owner's explicit consent.
Which types of websites most commonly allow web scraping?
Finance sites (Yahoo Finance, Google Finance), sports reference sites, weather platforms, public government databases, job boards, and travel booking sites are among the most common categories that permit scraping. Many provide official APIs to make structured data access even easier.
📚 Keep reading: For more interesting content, check out these articles on scraping social media platforms, including:



.avif)



























.avif)






















.avif)




























.avif)





.avif)